






Benchmarks
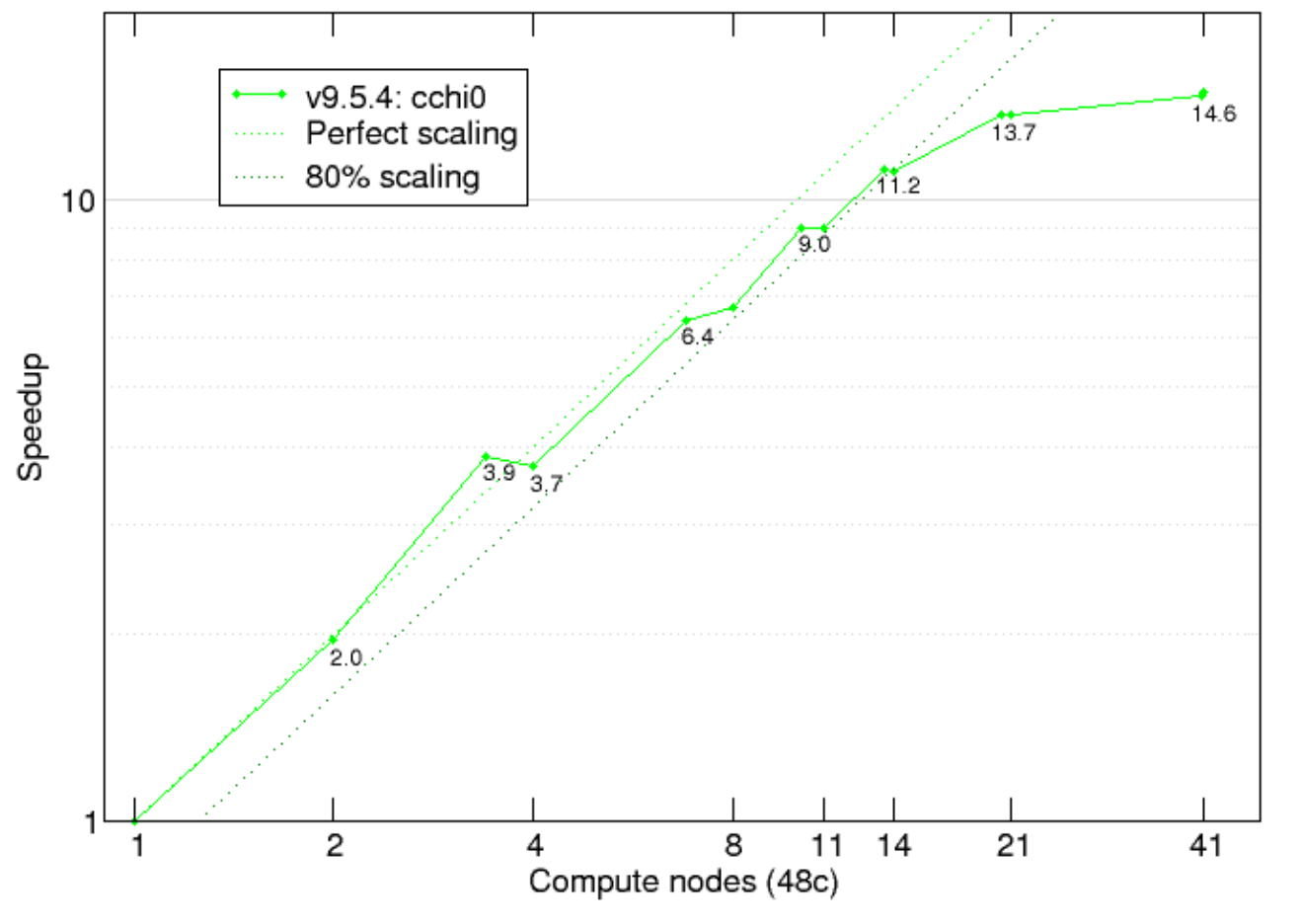
Feature tested:
Screening part of a GW calculation: optdriver 3
System tested:
11 atom Zr2Y2O7/C1 crystalline structure [nband=2000, nelect=88, empty(active)=1956; 36 q-points]
Abinit version: 9.5.4
Compilation options:
Fortran90 (and some C) parallelized with MPI with -O2 -xCORE-AVX512 -mtune=skylake Intel 2017.4 compilers and MPI libraries, with MKL BLAS/LAPACK & DFTI-FFT, NetCDF/HDF5
Hardware:
MareNostrum 4 on the highmem compute node (7928 MB per core) which has 2 sockets Intel Xeon Platinum 8160 CPU with 24 cores each @2.10GHz for a total of 48 cores per node. L1d 32K; L1i cache 32K; L2 cache 1024K; L3 cache 33792K. 100 Gbit/s Intel Omni-Path HFI Silicon 100 Series PCI-E adapter.
Source: Link
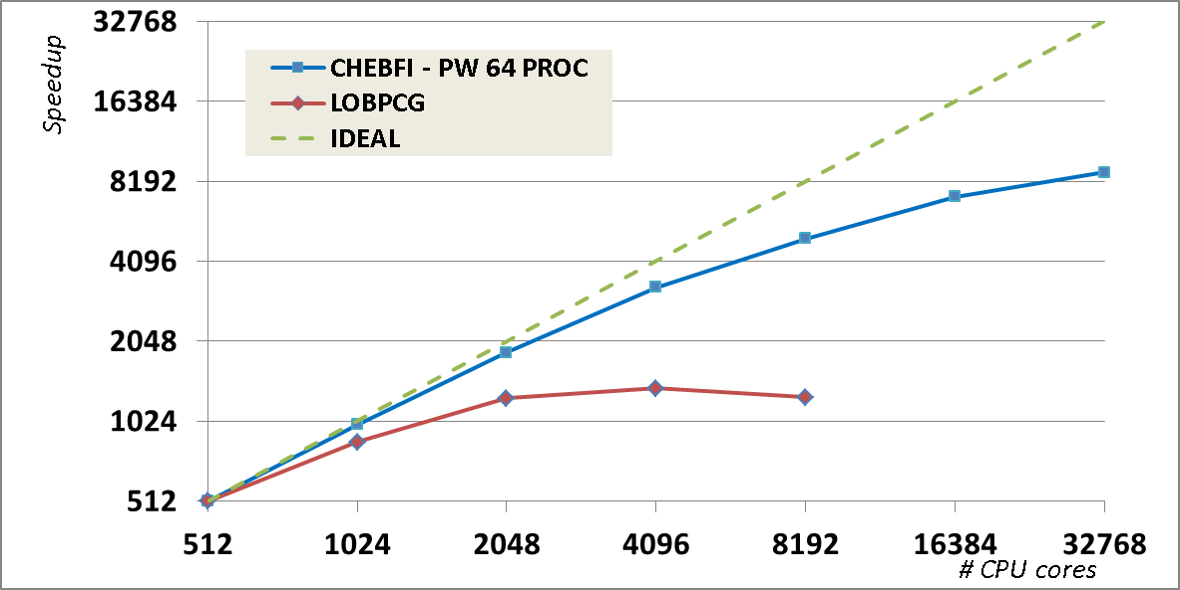
Feature tested:
Ground-state calculation - self-consistent DFT with different diagonalization algorithms.
System tested:
512 atoms of Ti with PAW pseudopotential [nband=4096]
Abinit version: 7.10
Compilation options:
We used the Intel MKL library for BLAS and LAPACK dense linear algebra, and the ELPA library for the dense eigenproblem in the Rayleigh–Ritz step (in our tests, we found it was about twice as fast as ScaLAPACK).
Hardware:
Curie supercomputer with 16-core Intel Nehalem-EX X7560 @ 2.26 GHz processors per node.
Source: A. Levitt and M. Torrent, Comput. Phys. Commun. 187, 98 (2015).
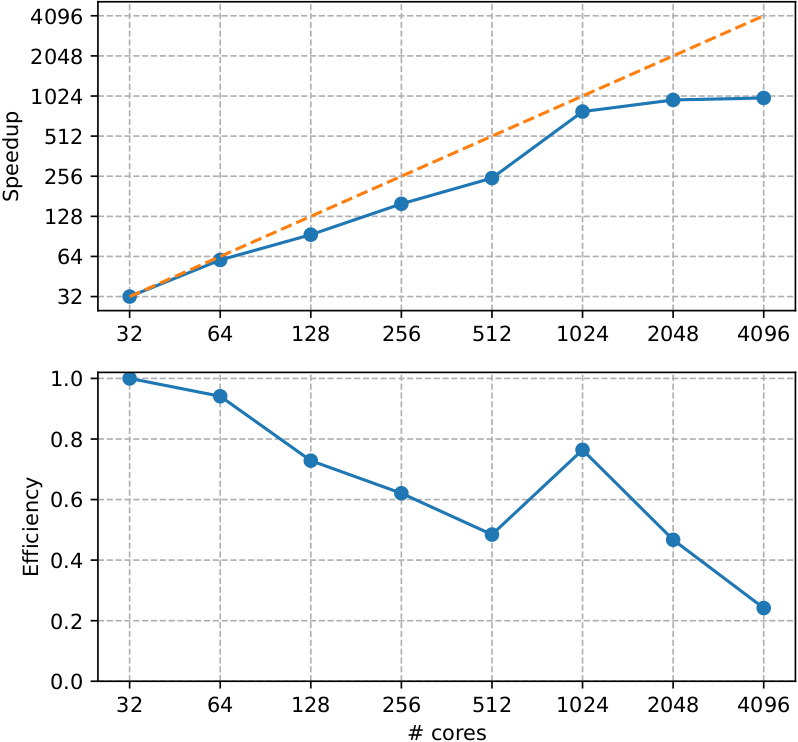
Feature tested:
Ground-state calculation - self-consistent DFT
System tested:
Ti metal, 3 atoms/cell l 80x80x80 dense k-mesh | 20 bands
Abinit version: 9.8.1
Compilation options:
Gnu 11.3 compiler with -g -02 and MPI
Hardware:
Lucia supercomputer AMD EPYC 7513 32C 2.6GHz with Mellanox HDR Infiniband
Additional note:
Until 512 cores only k-point parallelization is used while above there are additional parallelization levels on bands and fft, explaining the improved performance.
Source: Link
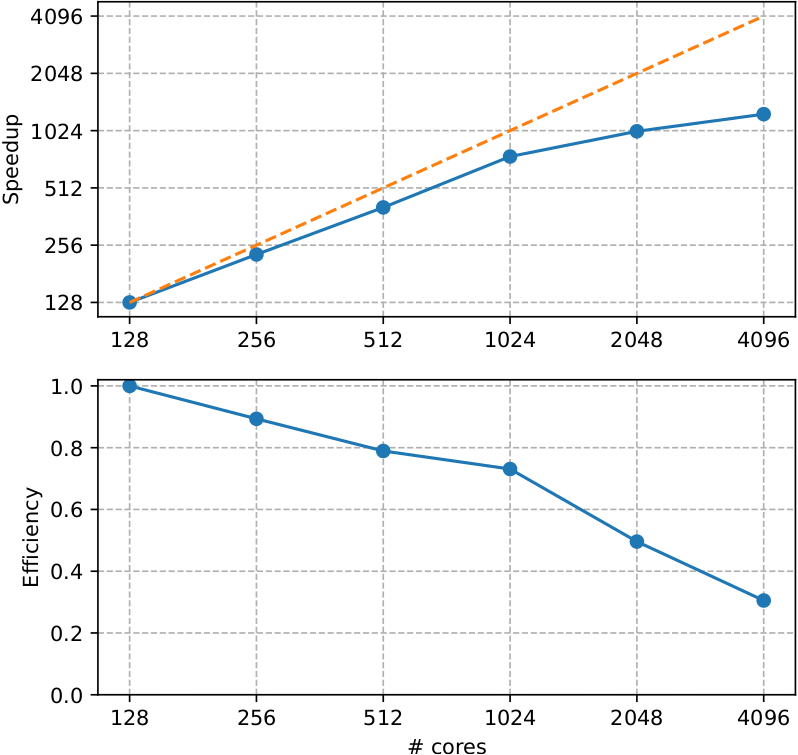
Feature tested:
Ground-state calculation - self-consistent DFT
System tested:
625 atoms supercell of LiSrH3 with one Eu(Sr) substitution l 1 k-point | 1024 bands | GGA+U on Eu-4f with PAW pseudos from Pseudo Dojo (JTH v1.1 PBE standard) | Paral over 2 spins, npbands, npfft, bandpp
Abinit version: 9.8.1
Compilation options:
Gnu 11.3 compiler with -g -02 and MPI
Hardware:
Lucia supercomputer AMD EPYC 7513 32C 2.6GHz with Mellanox HDR Infiniband
Source: Link

Feature tested:
Ground-state calculation - self-consistent DFT - Comparison between GPU and CPU
System tested:
512 atoms of Ti with PAW pseudopotential l 1 k-point | 4096 bands | GGA with PAW pseudos from Pseudo Dojo (JTH v1.1 PBE standard)
Abinit version: 9.9.3
Compilation options:
gfortran 11.2.0 -g -O2 using OpenMPI 4.1.4, Cuda 11.8, Kokkos 3.7.00, and mkl 22.3
Hardware:
CPU AMD EPYC 7H12 2*64 cores and GPU 4*Nvidia A100 40Gb
Feature tested:
Ground-state calculation - self-consistent DFT - Comparison between GPU and CPU
System tested:
512 atoms of Ti with PAW pseudopotential l 1 k-point | 2048 bands | ecut = 5 Ha | GGA with PAW pseudos from Pseudo Dojo (JTH v1.1 PBE standard)
Abinit version: 9.9.3
Compilation options:
Compiler NVHPC 22.11 -g --use_fast_math --compiler-options=-O3 with openMP target + cuda